
近日,国际人工智能顶级会议AAAI 2021公布了论文录取结果。AAAI是人工智能领域 悠久、涵盖内容 为广泛的国际顶级学术会议之一。AAAI 2021一共收到9034篇论文提交,其中有效审稿的数量为7911篇, 终录取数量为1692篇,录取率为21.4%。
AAAI(Association for the Advance of Artificial Intelligence), 即美国人工智能协会,是人工智能领域的主要学术组织之一,其主办的年会也是人工智能领域的国际顶级会议。在中国计算机学会的国际学术会议排名以及清华大学新发布的计算机科学推荐学术会议和期刊列表中,AAAI 均被列为人工智能领域的 A 类顶级会议。
本次AAAI 腾讯优图实验室共入选了11篇论文,涉及动作识别、人群密度估计、人脸安全等领域,展现了腾讯在计算机视觉领域的技术实力。
以下为部分腾讯优图入选AAAI 2021的论文:
01
学习用于动作识别的全面运动特征表达
Learning Comprehensive Motion Representation for Action Recognition
运动特征在动作识别中起到非常重要的作用。基于2D CNN的方法虽然高效,但是由于对每一帧都采用相同的二维卷积核,会产生大量的冗余和重复特征。近期有一些工作通过建立帧间的联系获取运动信息,但是依然存在感受野有限的问题。此外,特征的增强依旧只在通道或者空间维度单独进行。为了解决这些问题,腾讯优图首先提出了一个通道特征增强模块(CME)自适应地增强与运动相关的通道。增强系数通过分析整段视频的信息获得。根据相邻特征图之间的点对点相似性,腾讯优图进一步提出了一种空间运动增强(SME)模块,以指导模型集中于包含运动关键目标的区域,其背后的直觉是背景区域的变化通常比视频的运动区域慢。 通过将CME和SME集成到现成的2D网络中,腾讯优图 终获得了用于动作识别的全面运动特征学习方法。 腾讯优图的方法在三个公共数据集上取得了有竞争力的表现:Something-Something V1&V2和Kinetics-400。 特别是在时序推理数据集Something-Something V1和V2上,当使用16帧作为输入时,腾讯优图的方法比之前 好的方法高2.3%和1.9%。
02
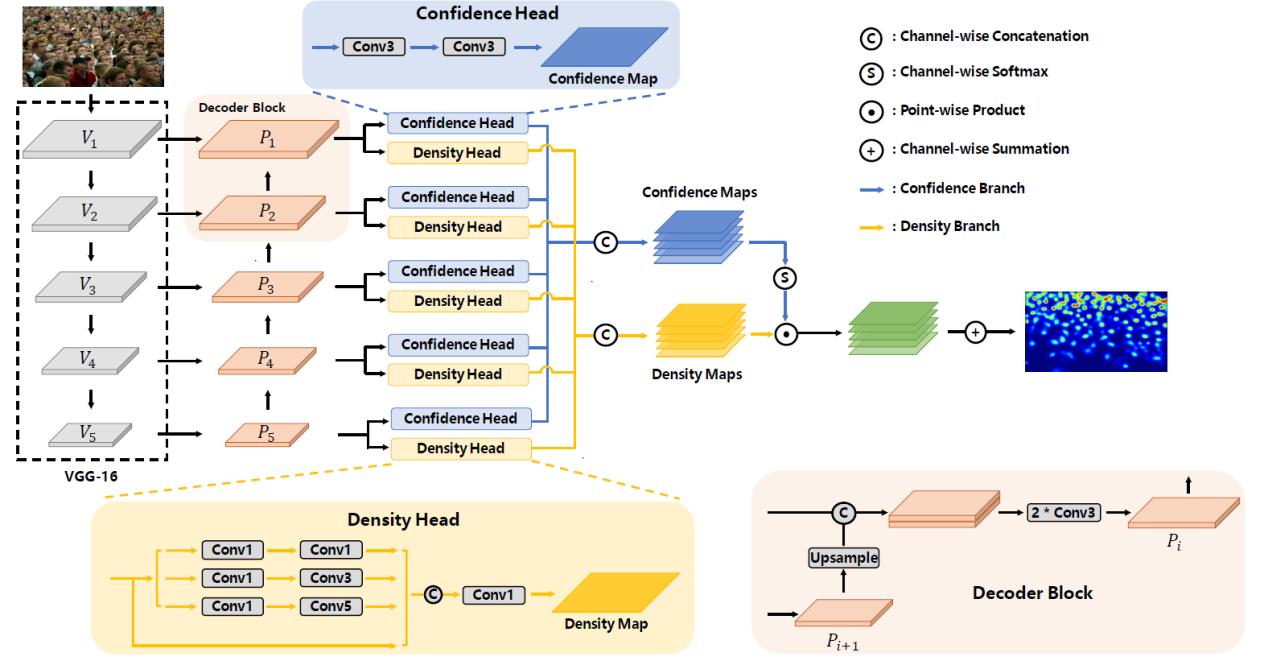
选择还是 ?基于自适应尺度选择的人群密度估计
To Choose or to Fuse? Scale Selection for Crowd Counting
本文提出了一种高效地充分利用网络内部多尺度特征表示的方法,能够有效解决人群密度估计中的大范围尺度变化问题。具体地,考虑到每层特征都有各自 擅长预测的人群尺度范围,本文提出了一种图像块级别的特征层选择策略来实现尽可能小的计数误差。显然,在没有人群尺度标注信息的情况下,任何人工指定人群尺度与特征层对应关系的方法都是次优的并会带来额外误差。相反地,本文提出的尺度自适应选择网络SASNet可以自动地学习这种对应关系,并通过软选择的方式来缓解离散的特征层与连续的人群尺度变化之间的矛盾。由于SASNet为同一图像块内相似尺度的人群选择同一特征层,直接使用传统的像素级损失函数会忽略图像块内部不同样本间各异的学习难度。因此,本文还提出了一种金字塔区域感知损失(PRA Loss),从图像块级别开始以一种自上而下的方式迭代地选择 困难的样本来优化。鉴于PRA Loss能够根据上层父图像块是过预测还是欠预测来选择困难样本,因此还能够缓解业界普遍面临的训练目标 小化和计数误差 小化之间不一致的问题。腾讯优图的方法在多达四个公开数据集上取得了优异的性能。
03
解耦场景和运动的无监督视频表征学习
Enhancing Unsupervised Video Representation Learning by Decoupling the Scene and the Motion
相比于图像表征学习, 视频表征学习中的一个重要因素是物体运动信息(Object Motion)。然而腾讯优图发现, 在当前主流的视频数据集中, 一些动作类别会和发生的场景强相关, 导致模型往往只关注了场景信息。比如, 模型可能仅仅因为发生的场景是足球场, 就将拉拉队员在足球场上跳舞的视频判断成了踢足球。这违背了视频表征学习 初的目的, 即学习物体运动信息, 并且不容忽视的是, 不同的数据集可能会带来不同的场景偏见(Scene Bias)。为了解决这个问题, 腾讯优图提出了用两个简单的操作来解耦合场景和运动(Decoupling the Scene and the Motion, DSM), 以此来到达让模型更加关注运动信息的目的。具体来说, 腾讯优图为每段视频都会构造一个正样本和一个负样本, 相比于原始视频, 正样本的运动信息没有发生变化, 但场景被破坏掉了, 而负样本的运动信息发生了改变, 但场景信息基本被保留了下来。构造正负样本的操作分别叫做Spatial Local Disturbance和Temporal Local Disturbance。腾讯优图的优化目标是在隐空间在拉近正样本和原始视频的同时, 推远负样本。用这种方式, 场景带来的负面影响被削弱掉了, 而模型对时序也变得更加敏感。腾讯优图在两个任务上, 用不同的网络结构、不同的预训练数据集进行了实验验证, 发现腾讯优图方法在动作识别任务上, 在UCF101以及HMDB51数据集上分别超越当前学界领先水平8.1%以及8.8%。

04
版权声明:本文为原创文章,版权归 头条123 所有,欢迎 本文,转载请保留出处!
 助力中小微企业业绩倍增,腾讯智慧零售与高灯科技联手打造小店经济创新平台
助力中小微企业业绩倍增,腾讯智慧零售与高灯科技联手打造小店经济创新平台 腾讯QQ春节牛气冲天红包活动:射手、处女、天秤座答题 积极
腾讯QQ春节牛气冲天红包活动:射手、处女、天秤座答题 积极 近3亿出资!腾讯“缩表”下罕见出手 战略投资这家公司!
近3亿出资!腾讯“缩表”下罕见出手 战略投资这家公司! 腾讯视频VIP今日起正式调价:涨幅5元-20元不等!
腾讯视频VIP今日起正式调价:涨幅5元-20元不等! 腾讯首次披露三款自研芯片,一款已试产
腾讯首次披露三款自研芯片,一款已试产 游戏行业格局生变?一季报腾讯游戏增速放缓“焦虑”求解
游戏行业格局生变?一季报腾讯游戏增速放缓“焦虑”求解 腾讯控股:向2.29万员工授予合共8004807股奖励股份
腾讯控股:向2.29万员工授予合共8004807股奖励股份 康佳电视助力腾讯游戏发布会,探索大屏云游戏新风尚
康佳电视助力腾讯游戏发布会,探索大屏云游戏新风尚 腾讯音乐“重新”推出腾讯音兔 App ,再战短视频
腾讯音乐“重新”推出腾讯音兔 App ,再战短视频 腾讯安全推动修复安卓手机设计重大漏洞 产业链
腾讯安全推动修复安卓手机设计重大漏洞 产业链 万科大消息!郁亮等高管加仓 取消价格上限!复星、腾讯连续出手!
万科大消息!郁亮等高管加仓 取消价格上限!复星、腾讯连续出手! 探讨零售行业新方向 腾讯《2018智慧零售研究报告
探讨零售行业新方向 腾讯《2018智慧零售研究报告 中国音乐市场复兴之路:正版化率高达96%,腾讯
中国音乐市场复兴之路:正版化率高达96%,腾讯 为什么说腾讯音乐娱乐在全球音乐产业中独一无
为什么说腾讯音乐娱乐在全球音乐产业中独一无 从“互联网+”到“云+智慧产业”,腾讯的“三联
从“互联网+”到“云+智慧产业”,腾讯的“三联 用前沿技术为生活添彩 腾讯优图 “AI画廊”于2021重庆智博会初次登场
用前沿技术为生活添彩 腾讯优图 “AI画廊”于2021重庆智博会初次登场 做好连接器 企业微信将成为腾讯产业互联网的一
做好连接器 企业微信将成为腾讯产业互联网的一 腾讯、网易发布五一未成年人限玩日历,打游戏
腾讯、网易发布五一未成年人限玩日历,打游戏 外卖的下半场战事 阿里腾讯间的“斗法”
外卖的下半场战事 阿里腾讯间的“斗法” 四川省教育厅携手腾讯教育发起《学习强师》,腾讯英语君以AI技术助力乡村教育振兴
四川省教育厅携手腾讯教育发起《学习强师》,腾讯英语君以AI技术助力乡村教育振兴